The Rise of AI Engineering
The Rise of AI Engineering
Foundation models emerged from large language models, which, in turn, originated as just language models. While applications like ChatGPT and GitHub Copilot may seem to have come out of nowhere, they are the culmination of decades of technology advancements — with the first language models emerging in the 1950s.
This section traces the key breakthroughs that enabled the evolution from language models to AI engineering.
From Language Models to Large Language Models
Language models have been around for a while, but they've only been able to grow to the scale they are today with self-supervision. This section gives a quick overview of what language model and self-supervision mean.
Language Models
A language model encodes statistical information about one or more languages. Intuitively, this information tells us how likely a word is to appear in a given context. For example, given the context My favorite color is, a language model that encodes English should predict blue more often than car.
The statistical nature of languages was discovered centuries ago.
1905 — Sherlock Holmes
1951 — Claude Shannon
Tokens
The basic unit of a language model is a token. A token can be a character, a word, or a part of a word (like -tion), depending on the model. For non-English languages, a single Unicode character can sometimes be represented as multiple tokens.
For example, GPT-4 — the model behind ChatGPT — breaks the phrase I can't wait to build AI applications into nine tokens. Note that the word can't is broken into two tokens, can and 't. You can see how different OpenAI models tokenize text on the OpenAI website.
 Figure 1-1. An example of how GPT-4 tokenizes a phrase.
Figure 1-1. An example of how GPT-4 tokenizes a phrase.
The process of breaking the original text into tokens is called tokenization. For GPT-4, an average token is approximately ¾ the length of a word. So, 100 tokens are approximately 75 words.
The set of all tokens a model can work with is the model's vocabulary. You can use a small number of tokens to construct a large number of distinct words, similar to how you can use a few letters in the alphabet to construct many words.
Mixtral 8x7B
GPT-4
The tokenization method and vocabulary size are decided by model developers.
- Compared to characters, tokens allow the model to break words into meaningful components. For example,
cookingcan be broken intocookanding, with both components carrying some meaning of the original word. - Because there are fewer unique tokens than unique words, this reduces the model's vocabulary size, making the model more efficient (as discussed in Chapter 2).
- Tokens also help the model process unknown words. For instance, a made-up word like
chatgptingcould be split intochatgptanding, helping the model understand its structure.
Two Main Types of Language Models
There are two main types of language models. They differ based on what information they can use to predict a token.
Masked Language Model
Trained to predict missing tokens anywhere in a sequence, using context from both before and after the missing tokens. Essentially trained to fill in the blank.
Example: given My favorite __ is blue, predict color.
A well-known example is BERT (Devlin et al., 2018). Today, masked language models are commonly used for non-generative tasks like sentiment analysis, text classification, and code debugging — where understanding the overall context matters.
Autoregressive Language Model
Trained to predict the next token in a sequence, using only the preceding tokens. It predicts what comes next in My favorite color is __.
An autoregressive model can continually generate one token after another. Today, autoregressive language models are the models of choice for text generation and are far more popular than masked language models. (Sometimes referred to as causal language models.)
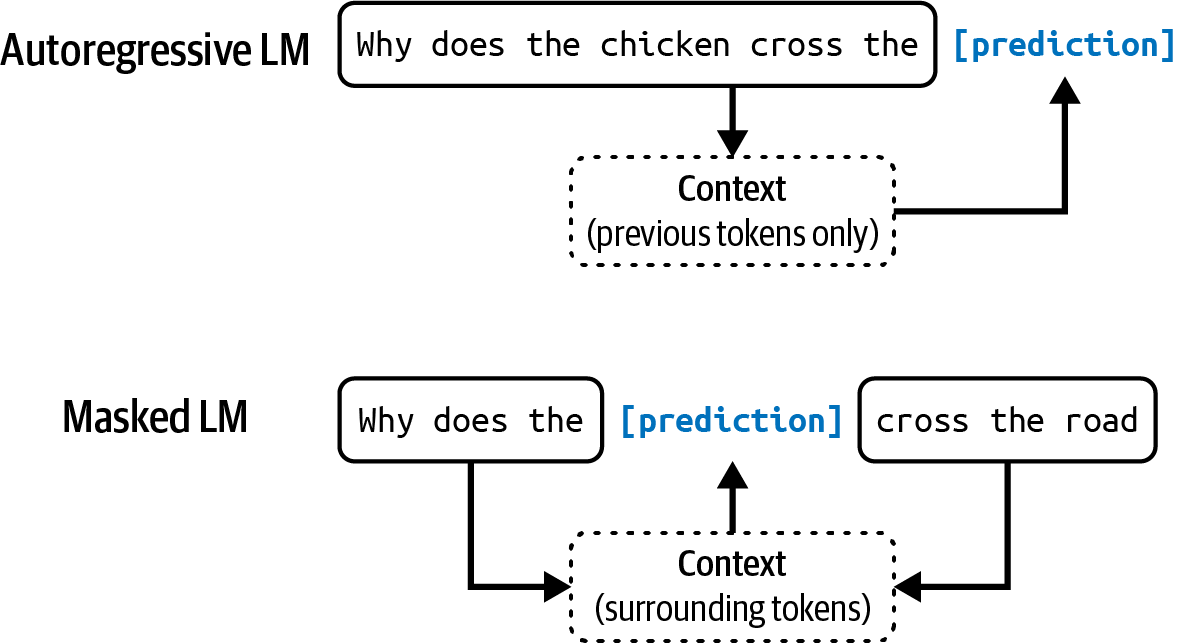 Figure 1-2. Autoregressive language model and masked language model.
Figure 1-2. Autoregressive language model and masked language model.
Language Models as Completion Machines
The outputs of language models are open-ended. A language model can use its fixed, finite vocabulary to construct infinite possible outputs. A model that can generate open-ended outputs is called generative — hence the term generative AI.
You can think of a language model as a completion machine: given a text (prompt), it tries to complete that text.
Prompt (from user): "To be or not to be"
Completion (from model): ", that is the question."
As simple as it sounds, completion is incredibly powerful. Many tasks — translation, summarization, coding, and solving math problems — can be framed as completion tasks.
Translation
Prompt: How are you in French is …
Completion: Comment ça va
Spam Classification
Prompt: Is this email likely spam? Here's the email: <email content>. Answer:
Completion: Likely spam
Self-Supervision
Language modeling is just one of many ML algorithms. There are also models for object detection, topic modeling, recommender systems, weather forecasting, stock price prediction, and more. What's special about language models that made them the center of the scaling approach behind the ChatGPT moment?
Supervision vs. Self-Supervision
Supervision
You label examples to show the behaviors you want the model to learn, then train the model on these examples.
Example: to train a fraud detection model, you use transactions each labeled fraud or not fraud.
The success of AI models in the 2010s lay in supervision. AlexNet (Krizhevsky et al., 2012), the model that started the deep learning revolution, was supervised — trained on ImageNet to classify over 1 million images into 1,000 categories such as car, balloon, or monkey.
Self-Supervision
Instead of requiring explicit labels, the model infers labels from the input data. Language modeling is self-supervised because each input sequence provides both the labels (tokens to be predicted) and the context for predicting them.
Because text sequences are everywhere — books, blog posts, articles, Reddit comments — it's possible to construct a massive amount of training data, allowing language models to scale up to LLMs.
For example, the sentence I love street food. gives six self-supervised training samples:
| Input (context) | Output (next token) |
|---|---|
<BOS> | I |
<BOS>, I | love |
<BOS>, I, love | street |
<BOS>, I, love, street | food |
<BOS>, I, love, street, food | . |
<BOS>, I, love, street, food, . | <EOS> |
Table 1-1. Training samples from the sentence I love street food. for language modeling.
<BOS> and <EOS> mark the beginning and the end of a sequence. These markers are necessary for a language model to work with multiple sequences. Each marker is typically treated as one special token by the model. The end-of-sequence marker is especially important — it helps language models know when to end their responses (similar to how it's important for humans to know when to stop talking).
From Language Models to LLMs
Self-supervised learning means language models can learn from text sequences without requiring any labeling. Because text is everywhere, it's possible to construct massive training datasets — allowing language models to scale up to become LLMs.
A model's size is typically measured by its number of parameters. A parameter is a variable within an ML model that is updated through the training process. (In school, parameters were taught as a combination of weights and biases. Today, we generally use model weights to refer to all parameters.) In general — though not always — the more parameters a model has, the greater its capacity to learn desired behaviors.
June 2018 — GPT-1
117 million parameters. Considered large at the time.
February 2019 — GPT-2
1.5 billion parameters. 117 million was downgraded to "small."
Today
A model with 100 billion parameters is considered large. Perhaps one day, this size will be considered small.
From Large Language Models to Foundation Models
While language models are capable of incredible tasks, they are limited to text. As humans, we perceive the world not just via language but also through vision, hearing, touch, and more. Being able to process data beyond text is essential for AI to operate in the real world.
For this reason, language models are being extended to incorporate more data modalities. GPT-4V and Claude 3 can understand images and texts. Some models even understand videos, 3D assets, protein structures, and more.
Incorporating additional modalities (such as image inputs) into LLMs is viewed by some as a key frontier in AI research and development. — OpenAI, GPT-4V system card, 2023
While many people still call Gemini and GPT-4V LLMs, they're better characterized as foundation models. The word foundation signifies both the importance of these models in AI applications and the fact that they can be built upon for different needs.
A Breakthrough From the Old Structure of AI Research
For a long time, AI research was divided by data modalities. Each branch handled its own type of input, with little overlap.
NLP
Computer Vision
Audio
A model that can work with more than one data modality is also called a multimodal model. A generative multimodal model is also called a large multimodal model (LMM). If a language model generates the next token conditioned on text-only tokens, a multimodal model generates the next token conditioned on both text and image tokens — or whichever modalities the model supports.
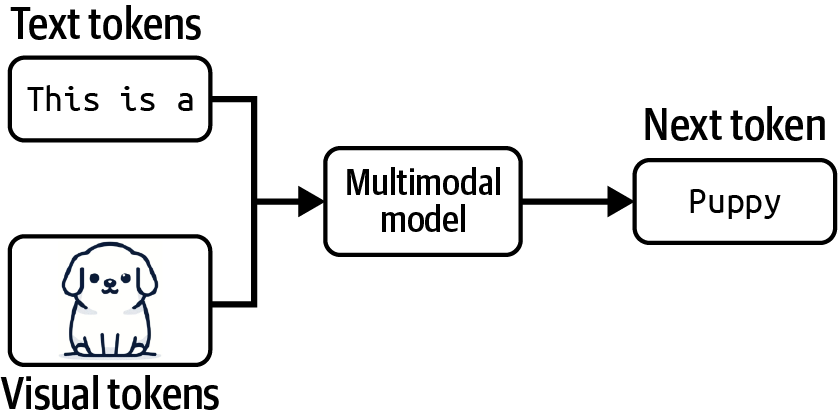 Figure 1-3. A multimodal model can generate the next token using information from both text and visual tokens.
Figure 1-3. A multimodal model can generate the next token using information from both text and visual tokens.
Just like language models, multimodal models need data to scale up. Self-supervision works for them too. OpenAI used a variant called natural language supervision to train CLIP (OpenAI, 2021). Instead of manually generating labels for each image, they found (image, text) pairs that co-occurred on the internet — yielding a dataset of 400 million pairs, 400× larger than ImageNet, with no manual labeling cost.
CLIP isn't a generative model — it wasn't trained to generate open-ended outputs. CLIP is an embedding model, trained to produce joint embeddings of texts and images. "Introduction to Embedding" on page 134 discusses embeddings in detail; for now, you can think of embeddings as vectors that aim to capture the meanings of the original data. Multimodal embedding models like CLIP are the backbones of generative multimodal models such as Flamingo, LLaVA, and Gemini (previously Bard).
From Task-Specific to General-Purpose
Foundation models also mark the transition from task-specific models to general-purpose models. Previously, models were often developed for specific tasks, such as sentiment analysis or translation. A model trained for sentiment analysis wouldn't be able to do translation, and vice versa.
 Figure 1-4. The range of tasks in the Super-Natural-Instructions benchmark (Wang et al., 2022).
Figure 1-4. The range of tasks in the Super-Natural-Instructions benchmark (Wang et al., 2022).
Adapting a Model to Your Needs
Imagine you're working with a retailer to build an application to generate product descriptions for their website. An out-of-the-box model might generate accurate descriptions but fail to capture the brand's voice or highlight the brand's messaging. The generated descriptions might even be full of marketing speech and clichés.
There are three common AI engineering techniques to adapt a model to your needs. The rest of the book will discuss all of them in detail.
Prompt Engineering
Retrieval-Augmented Generation (RAG)
Finetuning
From Foundation Models to AI Engineering
AI engineering refers to the process of building applications on top of foundation models. People have been building AI applications for over a decade — a process often known as ML engineering or MLOps (short for ML operations). Why do we talk about AI engineering now?
The availability and accessibility of powerful foundation models lead to three factors that, together, create ideal conditions for the rapid growth of AI engineering as a discipline.
Three Factors Driving the Growth of AI Engineering
Factor 1 — General-Purpose AI Capabilities
Foundation models are powerful not just because they can do existing tasks better — they can do more tasks. Applications previously thought impossible are now possible, and applications not thought of before are emerging. Even applications not thought possible today might be possible tomorrow. This vastly increases both the user base and the demand for AI applications.
Since AI can now write as well as humans (sometimes even better), it can automate or partially automate every task that requires communication — which is pretty much everything. AI is used to write emails, respond to customer requests, and explain complex contracts. Anyone with a computer has access to tools that can instantly generate customized, high-quality images and videos to create marketing materials, edit professional headshots, visualize art concepts, illustrate books, and more. AI is even used to synthesize training data, develop algorithms, and write code — all of which will help train even more powerful models in the future.
Factor 2 — Increased AI Investments
The success of ChatGPT prompted a sharp increase in investments in AI, both from venture capitalists and enterprises. As AI applications become cheaper to build and faster to go to market, returns on investment for AI become more attractive. Companies rush to incorporate AI into their products and processes.
Matt Ross, a senior manager of applied research at Scribd, told me that the estimated AI cost for his use cases has gone down two orders of magnitude from April 2022 to April 2023.
Goldman Sachs Research estimated that AI investment could approach $100 billion in the US and $200 billion globally by 2025. (For comparison, the entire US expenditure on public elementary and secondary schools is around $900 billion — only nine times the projected investment in AI in the US.)
AI is often mentioned as a competitive advantage. FactSet found that one in three S&P 500 companies mentioned AI in their earnings calls for Q2 2023 — three times more than the year earlier. According to WallStreetZen, companies that mentioned AI in their earnings calls saw their stock price increase more than those that didn't — an average 4.6% increase compared to 2.4%. It's unclear whether it's causation (AI makes these companies more successful) or correlation (companies are successful because they're quick to adapt to new technologies).
Factor 3 — Low Entrance Barrier to Building AI Applications
The model-as-a-service approach popularized by OpenAI and other model providers makes it easier to leverage AI to build applications. Models are exposed via APIs that receive user queries and return outputs — giving you access to powerful models via single API calls, without the infrastructure to host and serve them yourself.
AI also makes it possible to build applications with minimal coding:
- AI can write code for you, allowing people without a software engineering background to quickly turn their ideas into running applications and put them in front of their users.
- You can work with these models in plain English instead of a programming language.
Anyone, and I mean anyone, can now develop AI applications.
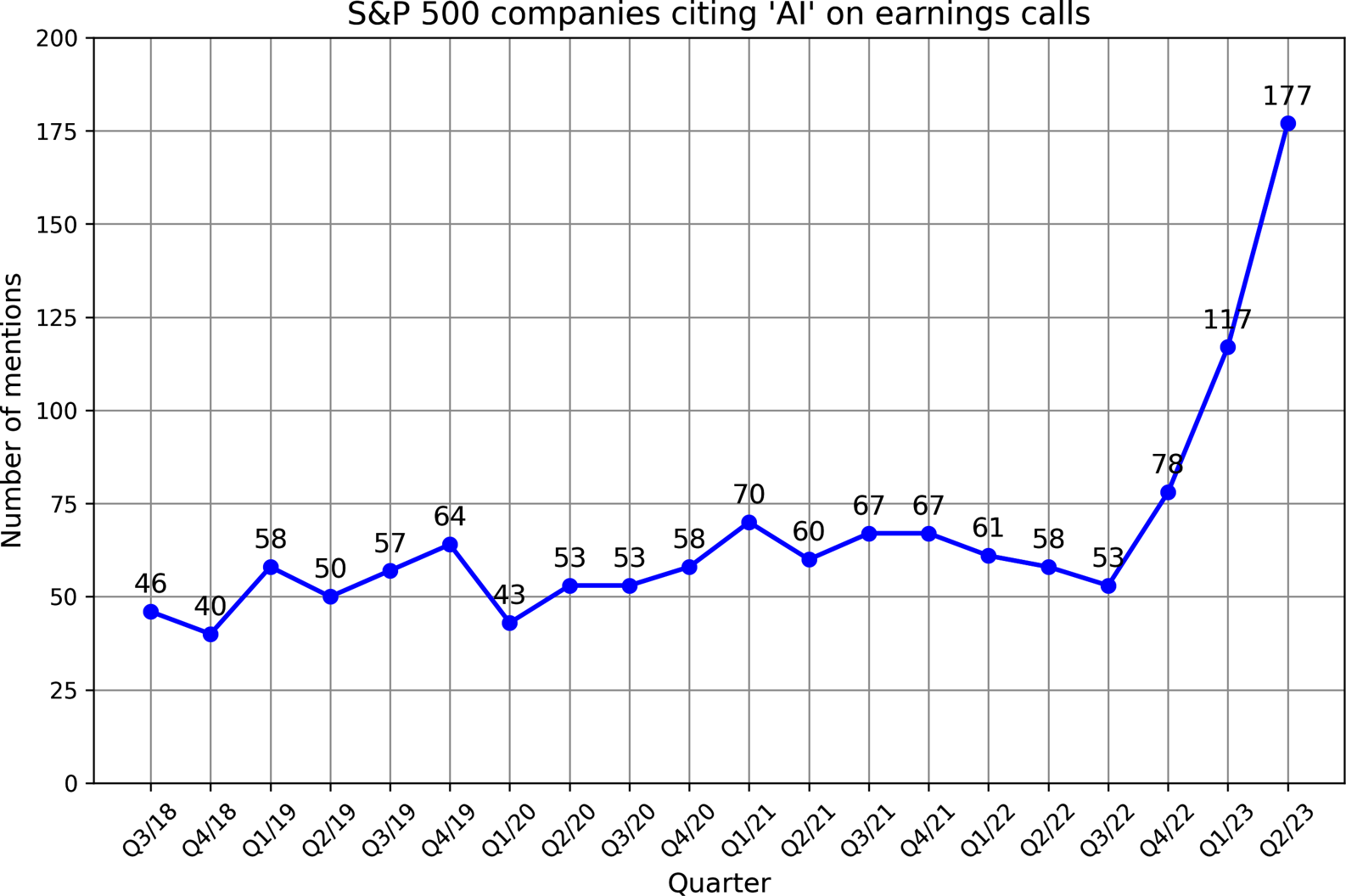 Figure 1-5. The number of S&P 500 companies that mention AI in their earnings calls reached a record high in 2023. Data from FactSet.
Figure 1-5. The number of S&P 500 companies that mention AI in their earnings calls reached a record high in 2023. Data from FactSet.
The Fastest-Growing Engineering Discipline
The world is quick to embrace this opportunity. AI engineering has rapidly emerged as one of the fastest — quite possibly the fastest — growing engineering disciplines. Tools for AI engineering are gaining traction faster than any previous software engineering tools.
Faster Than Bitcoin
Catching React and Vue
75% Monthly Profile Growth
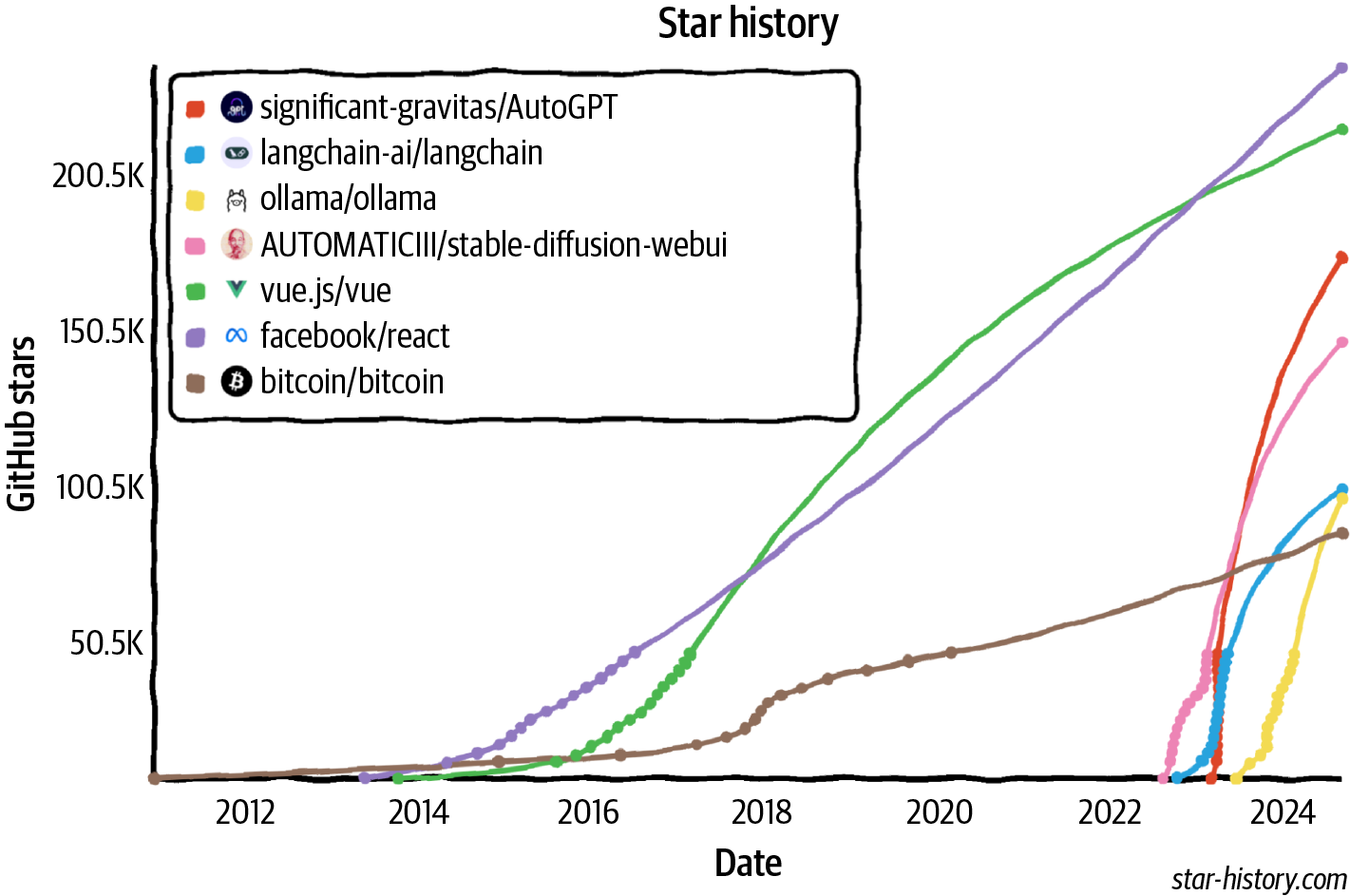 Figure 1-6. Open source AI engineering tools are growing faster than any other software engineering tools, according to their GitHub star counts.
Figure 1-6. Open source AI engineering tools are growing faster than any other software engineering tools, according to their GitHub star counts.
Teaching AI to behave is the fastest-growing career skill. — ComputerWorld
Why the Term "AI Engineering"?
Many terms are used to describe the process of building applications on top of foundation models — ML engineering, MLOps, AIOps, LLMOps, and so on. Why did I choose to go with AI engineering for this book?
Introduction to Building AI Applications with Foundation Models
How the scaling of foundation models reshaped AI, lowered the barrier to building applications, and turned AI engineering into one of the fastest-growing disciplines in software.
Foundation Model Use Cases
A tour of industry-proven and promising use cases for foundation models — from coding and creative work to writing, education, chatbots, information aggregation, data organization, and workflow automation.