The AI Engineering Stack
The AI Engineering Stack
AI engineering's rapid growth induced an incredible amount of hype and FOMO. The number of new tools, techniques, models, and applications introduced every day can be overwhelming.
Instead of chasing constantly shifting sand, let's look into the fundamental building blocks of AI engineering.
Where AI Engineering Comes From
To understand AI engineering, it's important to recognize that AI engineering evolved out of ML engineering. When a company starts experimenting with foundation models, it's natural that its existing ML team should lead the effort. Some companies treat AI engineering the same as ML engineering, as shown in Figure 1-12.
{kind=link}
Figure 1-12. Many companies put AI engineering and ML engineering under the same
Some companies have separate job descriptions for AI engineering, as shown in Figure 1-13.
{kind=link}
Figure 1-13. Some companies have separate job descriptions for AI engineering, as shown in the job headlines on LinkedIn from December 17, 2023.
To best understand AI engineering and how it differs from traditional ML engineering, the following section breaks down different layers of the AI application building process and looks at the role each layer plays in AI engineering and ML engineering.
Three Layers of the AI Stack
There are three layers to any AI application stack. When developing an AI application, you'll likely start from the top layer and move down as needed:
Application Development
Model Development
Infrastructure
These three layers and examples of responsibilities for each layer are shown in Figure 1-14.
{kind=link}
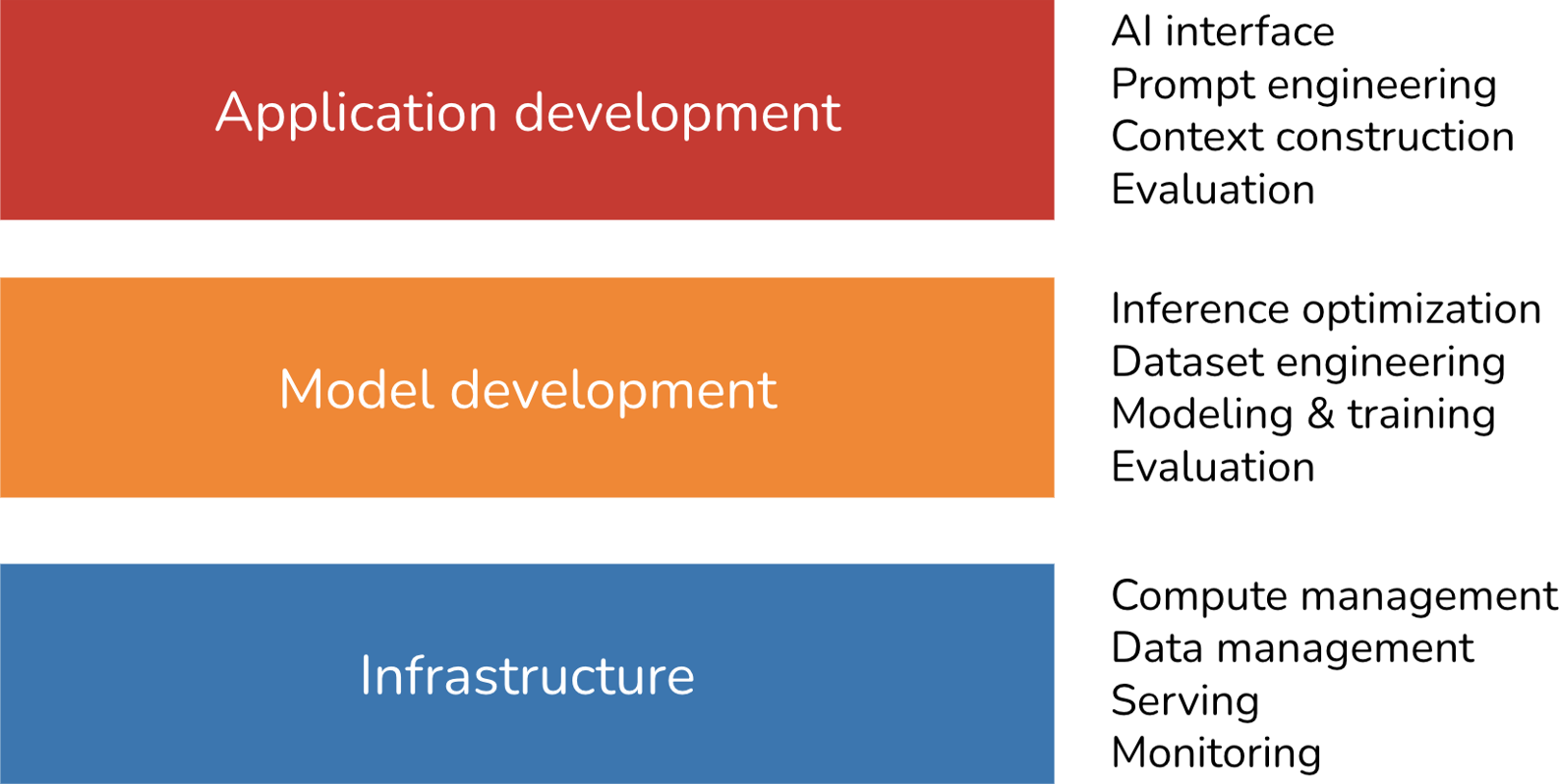
Figure 1-14. Three layers of the AI engineering stack.
To get a sense of how the landscape has evolved with foundation models, in March 2024, I searched GitHub for all AI-related repositories with at least 500 stars. Given the prevalence of GitHub, I believe this data is a good proxy for understanding the ecosystem. In my analysis, I also included repositories for applications and models, which are the products of the application development and model development layers, respectively. I found a total of 920 repositories. Figure 1-15 shows the cumulative number of repositories in each category month-over-month.
{kind=link}
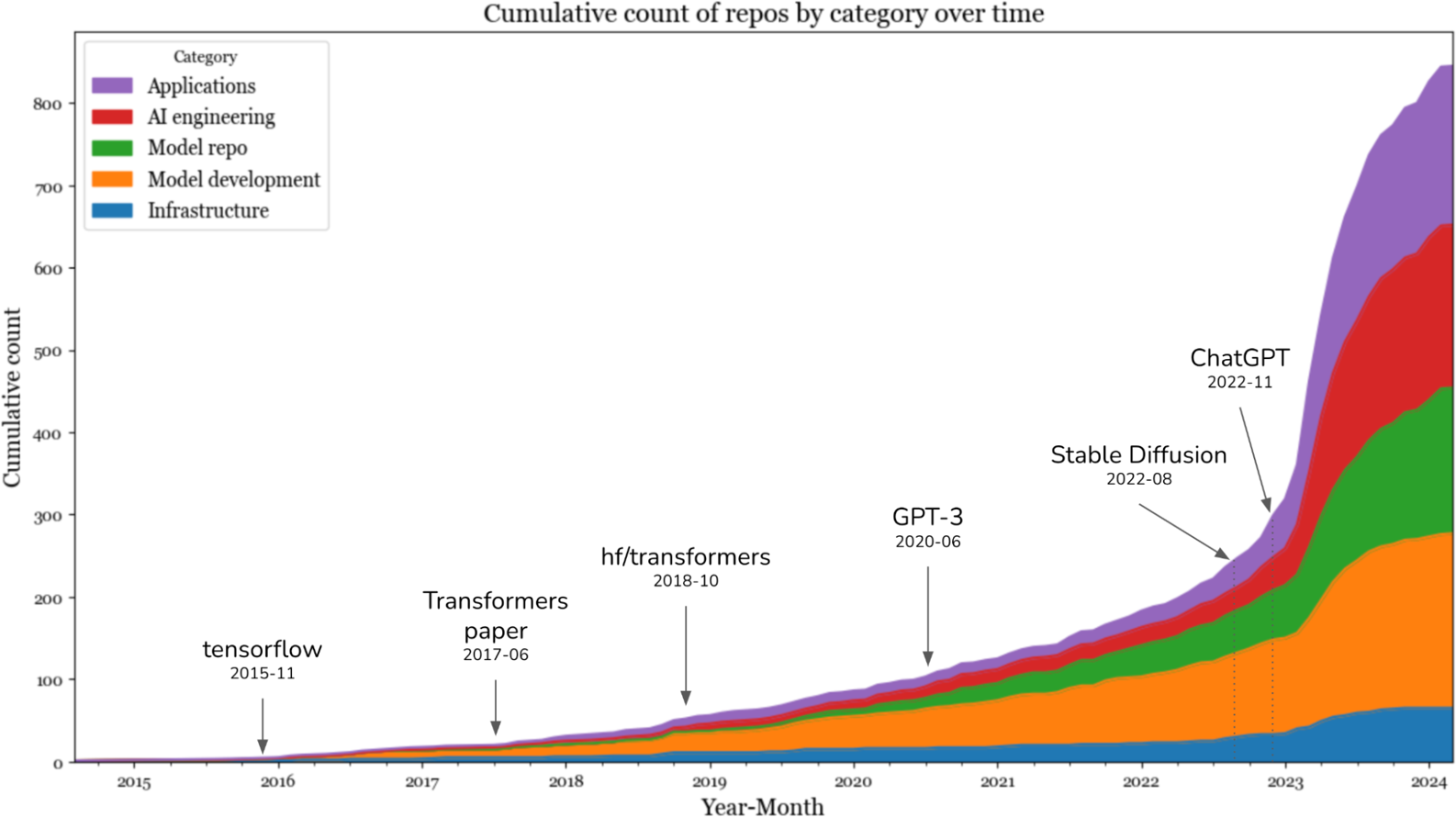
Figure 1-15. Cumulative count of repositories by category over time.
While the level of excitement and creativity around foundation models is unprecedented, many principles of building AI applications remain the same. For enterprise use cases, AI applications still need to solve business problems, and, therefore, it's still essential to map from business metrics to ML metrics and vice versa. You still need to do systematic experimentation. With classical ML engineering, you experiment with different hyperparameters. With foundation models, you experiment with different models, prompts, retrieval algorithms, sampling variables, and more. (Sampling variables are discussed in Chapter 2.) We still want to make models run faster and cheaper. It's still important to set up a feedback loop so that we can iteratively improve our applications with production data.
This means that much of what ML engineers have learned and shared over the last decade is still applicable. This collective experience makes it easier for everyone to begin building AI applications. However, built on top of these enduring principles are many innovations unique to AI engineering, which we'll explore in this book.
AI Engineering Versus ML Engineering
While the unchanging principles of deploying AI applications are reassuring, it's also important to understand how things have changed. This is helpful for teams that want to adapt their existing platforms for new AI use cases and developers who are interested in which skills to learn to stay competitive in a new market.
At a high level, building applications using foundation models today differs from traditional ML engineering in three major ways:
Pre-trained models replace training your own
Without foundation models, you have to train your own models for your applications. With AI engineering, you use a model someone else has trained for you. This means that AI engineering focuses less on modeling and training, and more on model adaptation.
Bigger models, more compute pressure
AI engineering works with models that are bigger, consume more compute resources, and incur higher latency than traditional ML engineering. This means more pressure for efficient training and inference optimization. A corollary is that many companies now need more GPUs and work with bigger compute clusters than they previously did, creating more need for engineers who know how to work with GPUs and big clusters.1
Open-ended outputs make evaluation harder
AI engineering works with models that can produce open-ended outputs. Open-ended outputs give models the flexibility to be used for more tasks, but they are also harder to evaluate. This makes evaluation a much bigger problem in AI engineering.
In short, AI engineering differs from ML engineering in that it's less about model development and more about adapting and evaluating models. Before we move on, let's clarify what model adaptation means. In general, model adaptation techniques can be divided into two categories, depending on whether they require updating model weights.
Prompt-Based Techniques
Adapt a model without updating model weights. You adapt a model by giving it instructions and context instead of changing the model itself.
Prompt engineering is easier to get started and requires less data. Many successful applications have been built with just prompt engineering. Its ease of use lets you experiment with more models, increasing your chance of finding one that's unexpectedly good for your application.
However, it might not be enough for complex tasks or applications with strict performance requirements.
Finetuning
Adapt a model by updating model weights. You adapt a model by making changes to the model itself.
In general, finetuning techniques are more complicated and require more data, but they can improve quality, latency, and cost significantly.
Many things aren't possible without changing model weights, such as adapting a model to a new task it wasn't exposed to during training.
Now, let's zoom into the application development and model development layers to see how each has changed with AI engineering, starting with what existing ML engineers are more familiar with.
Model Development
Model development is the layer most commonly associated with traditional ML engineering. It has three main responsibilities: modeling and training, dataset engineering, and inference optimization. Evaluation is also required, but because most people will come across it first in the application development layer, I'll discuss evaluation in the next section.
Modeling and training
Modeling and training refers to the process of coming up with a model architecture, training it, and finetuning it. Examples of tools in this category are Google's TensorFlow, Hugging Face's Transformers, and Meta's PyTorch.
Developing ML models requires specialized ML knowledge. It requires knowing different types of ML algorithms (such as clustering, logistic regression, decision trees, and collaborative filtering) and neural network architectures (such as feedforward, recurrent, convolutional, and transformer). It also requires understanding how a model learns, including concepts such as gradient descent, loss function, regularization, etc.
Pre-training refers to training a model from scratch — the model weights are randomly initialized. For LLMs, pre-training often involves training a model for text completion.
Out of all training steps, pre-training is often the most resource-intensive by a long shot. For the InstructGPT model, pre-training takes up to 98% of the overall compute and data resources. Pre-training also takes a long time. A small mistake during pre-training can incur a significant financial loss and set back the project significantly.
Due to the resource-intensive nature of pre-training, this has become an art that only a few practice. Those with expertise in pre-training large models, however, are heavily sought after.2
Many people use post-training to refer to the process of training a model after the pre-training phase. Conceptually, post-training and finetuning are the same and can be used interchangeably. However, sometimes people use them differently to signify different goals.
- It's usually post-training when it's done by model developers. For example, OpenAI might post-train a model to make it better at following instructions before releasing it.
- It's finetuning when it's done by application developers. For example, you might finetune an OpenAI model (which might have been post-trained itself) to adapt it to your needs.
Pre-training and post-training make up a spectrum.3 Their processes and toolings are very similar. Their differences are explored further in Chapters 2 and 7.
Some people use the term training to refer to prompt engineering, which isn't correct. I read a Business Insider article where the author said she trained ChatGPT to mimic her younger self by feeding her childhood journal entries into ChatGPT.
Colloquially, the author's usage of the word training is correct, as she's teaching the model to do something. But technically, if you teach a model what to do via the context input into the model, you're doing prompt engineering. Similarly, I've seen people using the term finetuning when what they do is prompt engineering.
Dataset engineering
Dataset engineering refers to curating, generating, and annotating the data needed for training and adapting AI models.
Closed-Ended (Traditional ML)
Open-Ended (Foundation Models)
Another difference is that traditional ML engineering works more with tabular data, whereas foundation models work with unstructured data. In AI engineering, data manipulation is more about deduplication, tokenization, context retrieval, and quality control, including removing sensitive information and toxic data. Dataset engineering is the focus of Chapter 8.
Inference optimization
Inference optimization means making models faster and cheaper. Inference optimization has always been important for ML engineering. Users never say no to faster models, and companies can always benefit from cheaper inference. However, as foundation models scale up to incur even higher inference cost and latency, inference optimization has become even more important.
A summary of how the importance of different categories of model development change with AI engineering is shown in Table 1-4.
Table 1-4. How different responsibilities of model development have changed with foundation models.
| Category | Building with traditional ML | Building with foundation models |
|---|---|---|
| Modeling and training | ML knowledge is required for training a model from scratch | ML knowledge is a nice-to-have, not a must-have4 |
| Dataset engineering | More about feature engineering, especially with tabular data | Less about feature engineering and more about data deduplication, tokenization, context retrieval, and quality control |
| Inference optimization | Important | Even more important |
Inference optimization techniques, including quantization, distillation, and parallelism, are discussed in Chapters 7 through 9.
Application Development
With traditional ML engineering, where teams build applications using their proprietary models, the model quality is a differentiation. With foundation models, where many teams use the same model, differentiation must be gained through the application development process.
The application development layer consists of three responsibilities: evaluation, prompt engineering, and AI interface.
Evaluation
Evaluation is about mitigating risks and uncovering opportunities. Evaluation is necessary throughout the whole model adaptation process — to select models, to benchmark progress, to determine whether an application is ready for deployment, and to detect issues and opportunities for improvement in production.
While evaluation has always been important in ML engineering, it's even more important with foundation models. The challenges of evaluating foundation models are discussed in Chapter 3. To summarize, these challenges chiefly arise from foundation models' open-ended nature and expanded capabilities.
Closed-Ended Tasks
Open-Ended Tasks
The existence of so many adaptation techniques also makes evaluation harder. A system that performs poorly with one technique might perform much better with another. When Google launched Gemini in December 2023, they claimed that Gemini is better than ChatGPT in the MMLU benchmark (Hendrycks et al., 2020). Google had evaluated Gemini using a prompt engineering technique called CoT@32. In this technique, Gemini was shown 32 examples, while ChatGPT was shown only 5 examples. When both were shown five examples, ChatGPT performed better, as shown in Table 1-5.
Table 1-5. Different prompts can cause models to perform very differently, as seen in Gemini's technical report (December 2023).
| Gemini ultra | Gemini Pro | GPT-4 | GPT-3.5 | PaLM 2-L | Claude 2 | Inflection-2 | Grok 1 | Llama-2 | |
|---|---|---|---|---|---|---|---|---|---|
| MMLU performance | 90.04% CoT@32 | 79.13% CoT@8 | 87.29% CoT@32 (via API) | 70% 5-shot | 78.4% 5-shot | 78.5% 5-shot CoT | 79.6% 5-shot | 73.0% 5-shot | 68.0% |
| 83.7% 5-shot | 71.8% 5-shot | 86.4% 5-shot (reported) |
Prompt engineering and context construction
Prompt engineering is about getting AI models to express the desirable behaviors from the input alone, without changing the model weights. The Gemini evaluation story highlights the impact of prompt engineering on model performance. By using a different prompt engineering technique, Gemini Ultra's performance on MMLU went from 83.7% to 90.04%.
AI interface
AI interface means creating an interface for end users to interact with your AI applications. Before foundation models, only organizations with sufficient resources to develop AI models could develop AI applications. These applications were often embedded into the organizations' existing products. For example, fraud detection was embedded into Stripe, Venmo, and PayPal. Recommender systems were part of social networks and media apps like Netflix, TikTok, and Spotify.
With foundation models, anyone can build AI applications. You can serve your AI applications as standalone products or embed them into other products, including products developed by other people. For example, ChatGPT and Perplexity are standalone products, whereas GitHub Copilot is commonly used as a plug-in in VSCode, Grammarly as a browser extension for Google Docs, and Midjourney can be used via its standalone web app or via its integration in Discord.
Here are some of the interfaces that are gaining popularity for AI applications:
Standalone Apps
Browser Extensions
Chat App Integrations
Plug-ins & APIs
While the chat interface is the most commonly used, AI interfaces can also be voice-based (such as with voice assistants) or embodied (such as in augmented and virtual reality).
A summary of how the importance of different categories of app development changes with AI engineering is shown in Table 1-6.
Table 1-6. The importance of different categories in app development for AI engineering and ML engineering.
| Category | Building with traditional ML | Building with foundation models |
|---|---|---|
| AI interface | Less important | Important |
| Prompt engineering | Not applicable | Important |
| Evaluation | Important | More important |
AI Engineering Versus Full-Stack Engineering
The increased emphasis on application development, especially on interfaces, brings AI engineering closer to full-stack development.6 The rising importance of interfaces leads to a shift in the design of AI toolings to attract more frontend engineers.
Then — Python-centric ML
Now — JavaScript Joins
While many AI engineers come from traditional ML backgrounds, more are increasingly coming from web development or full-stack backgrounds. An advantage that full-stack engineers have over traditional ML engineers is their ability to quickly turn ideas into demos, get feedback, and iterate.

Figure 1-16. The new AI engineering workflow rewards those who can iterate fast. Image recreated from "The Rise of the AI Engineer" (Shawn Wang, 2023).
In traditional ML engineering, model development and product development are often disjointed processes, with ML engineers rarely involved in product decisions at many organizations. However, with foundation models, AI engineers tend to be much more involved in building the product.
Footnotes
- As the head of AI at a Fortune 500 company told me: his team knows how to work with 10 GPUs, but they don't know how to work with 1,000 GPUs. ↩
- And they are offered incredible compensation packages. ↩
- If you find the terms "pre-training" and "post-training" lacking in imagination, you're not alone. The AI research community is great at many things, but naming isn't one of them. We already talked about how "large language models" is hardly a scientific term because of the ambiguity of the word "large". And I really wish people would stop publishing papers with the title "X is all you need." ↩
- Many people would dispute this claim, saying that ML knowledge is a must-have. ↩
- Streamlit, Gradio, and Plotly Dash are common tools for building AI web apps. ↩
- Anton Bacaj told me that "AI engineering is just software engineering with AI models thrown in the stack." ↩